Speech & Audio
Audio source separation, recognition, and understanding.
Our current research focuses on application of machine learning to estimation and inference problems in speech and audio processing. Topics include end-to-end speech recognition and enhancement, acoustic modeling and analysis, statistical dialog systems, as well as natural language understanding and adaptive multimodal interfaces.
Quick Links
-
Researchers
-
Awards
-
AWARD MERL team wins the Listener Acoustic Personalisation (LAP) 2024 Challenge Date: August 29, 2024
Awarded to: Yoshiki Masuyama, Gordon Wichern, Francois G. Germain, Christopher Ick, and Jonathan Le Roux
MERL Contacts: François Germain; Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
The LAP Challenge workshop and award ceremony was hosted by the 32nd European Signal Processing Conference (EUSIPCO 24) on August 29, 2024 in Lyon, France. Yoshiki Masuyama presented the team's method, "Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization", and received the award from Prof. Michele Geronazzo (University of Padova, IT, and Imperial College London, UK), Chair of the Challenge's Organizing Committee.
The LAP challenge aims to explore challenges in the field of personalized spatial audio, with the first edition focusing on the spatial upsampling and interpolation of head-related transfer functions (HRTFs). HRTFs with dense spatial grids are required for immersive audio experiences, but their recording is time-consuming. Although HRTF spatial upsampling has recently shown remarkable progress with approaches involving neural fields, HRTF estimation accuracy remains limited when upsampling from only a few measured directions, e.g., 3 or 5 measurements. The MERL team tackled this problem by proposing a retrieval-augmented neural field (RANF). RANF retrieves a subject whose HRTFs are close to those of the target subject at the measured directions from a library of subjects. The HRTF of the retrieved subject at the target direction is fed into the neural field in addition to the desired sound source direction. The team also developed a neural network architecture that can handle an arbitrary number of retrieved subjects, inspired by a multi-channel processing technique called transform-average-concatenate.
- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
-
AWARD Jonathan Le Roux elevated to IEEE Fellow Date: January 1, 2024
Awarded to: Jonathan Le Roux
MERL Contact: Jonathan Le Roux
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
Mitsubishi Electric celebrated Dr. Le Roux's elevation and that of another researcher from the company, Dr. Shumpei Kameyama, with a worldwide news release on February 15.
Dr. Jonathan Le Roux has made fundamental contributions to the field of multi-speaker speech processing, especially to the areas of speech separation and multi-speaker end-to-end automatic speech recognition (ASR). His contributions constituted a major advance in realizing a practically usable solution to the cocktail party problem, enabling machines to replicate humans’ ability to concentrate on a specific sound source, such as a certain speaker within a complex acoustic scene—a long-standing challenge in the speech signal processing community. Additionally, he has made key contributions to the measures used for training and evaluating audio source separation methods, developing several new objective functions to improve the training of deep neural networks for speech enhancement, and analyzing the impact of metrics used to evaluate the signal reconstruction quality. Dr. Le Roux’s technical contributions have been crucial in promoting the widespread adoption of multi-speaker separation and end-to-end ASR technologies across various applications, including smart speakers, teleconferencing systems, hearables, and mobile devices.
IEEE Fellow is the highest grade of membership of the IEEE. It honors members with an outstanding record of technical achievements, contributing importantly to the advancement or application of engineering, science and technology, and bringing significant value to society. Each year, following a rigorous evaluation procedure, the IEEE Fellow Committee recommends a select group of recipients for elevation to IEEE Fellow. Less than 0.1% of voting members are selected annually for this member grade elevation.
- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date: December 16, 2023
Awarded to: Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
MERL Contacts: François Germain; Chiori Hori; Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems.
- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
See All Awards for Speech & Audio -
-
News & Events
-
EVENT MERL Contributes to ICASSP 2025 Date: Sunday, April 6, 2025 - Friday, April 11, 2025
Location: Hyderabad, India
MERL Contacts: Wael H. Ali; Petros T. Boufounos; Radu Corcodel; François Germain; Chiori Hori; Siddarth Jain; Devesh K. Jha; Toshiaki Koike-Akino; Jonathan Le Roux; Yanting Ma; Hassan Mansour; Yoshiki Masuyama; Joshua Rapp; Diego Romeres; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Communications, Computational Sensing, Electronic and Photonic Devices, Machine Learning, Robotics, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2025, which is being held in Hyderabad, India from April 6-11, 2025.
Sponsorship
MERL is proud to be a Silver Patron of the conference and will participate in the student job fair on Thursday, April 10. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns.
MERL is pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Björn Erik Ottersten, the recipient of the 2025 IEEE Fourier Award for Signal Processing, and Prof. Shrikanth Narayanan, the recipient of the 2025 IEEE James L. Flanagan Speech and Audio Processing Award. Both awards will be presented in-person at ICASSP by Anthony Vetro, MERL President & CEO.
Technical Program
MERL is presenting 15 papers in the main conference on a wide range of topics including source separation, sound event detection, sound anomaly detection, speaker diarization, music generation, robot action generation from video, indoor airflow imaging, WiFi sensing, Doppler single-photon Lidar, optical coherence tomography, and radar imaging. Another paper on spatial audio will be presented at the Generative Data Augmentation for Real-World Signal Processing Applications (GenDA) Satellite Workshop.
MERL Researchers Petros Boufounos and Hassan Mansour will present a Tutorial on “Computational Methods in Radar Imaging” in the afternoon of Monday, April 7.
Petros Boufounos will also be giving an industry talk on Thursday April 10 at 12pm, on “A Physics-Informed Approach to Sensing".
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event has been attracting more than 4000 participants each year.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2025, which is being held in Hyderabad, India from April 6-11, 2025.
-
NEWS MERL Researchers to Present 2 Conference and 11 Workshop Papers at NeurIPS 2024 Date: December 10, 2024 - December 15, 2024
Where: Advances in Neural Processing Systems (NeurIPS)
MERL Contacts: Petros T. Boufounos; Matthew Brand; Ankush Chakrabarty; Anoop Cherian; François Germain; Toshiaki Koike-Akino; Christopher R. Laughman; Jonathan Le Roux; Jing Liu; Suhas Lohit; Tim K. Marks; Yoshiki Masuyama; Kieran Parsons; Kuan-Chuan Peng; Diego Romeres; Pu (Perry) Wang; Ye Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Communications, Computational Sensing, Computer Vision, Control, Data Analytics, Dynamical Systems, Machine Learning, Multi-Physical Modeling, Optimization, Robotics, Signal Processing, Speech & Audio, Human-Computer Interaction, Information SecurityBrief- MERL researchers will attend and present the following papers at the 2024 Advances in Neural Processing Systems (NeurIPS) Conference and Workshops.
1. "RETR: Multi-View Radar Detection Transformer for Indoor Perception" by Ryoma Yataka (Mitsubishi Electric), Adriano Cardace (Bologna University), Perry Wang (Mitsubishi Electric Research Laboratories), Petros Boufounos (Mitsubishi Electric Research Laboratories), Ryuhei Takahashi (Mitsubishi Electric). Main Conference. https://neurips.cc/virtual/2024/poster/95530
2. "Evaluating Large Vision-and-Language Models on Children's Mathematical Olympiads" by Anoop Cherian (Mitsubishi Electric Research Laboratories), Kuan-Chuan Peng (Mitsubishi Electric Research Laboratories), Suhas Lohit (Mitsubishi Electric Research Laboratories), Joanna Matthiesen (Math Kangaroo USA), Kevin Smith (Massachusetts Institute of Technology), Josh Tenenbaum (Massachusetts Institute of Technology). Main Conference, Datasets and Benchmarks track. https://neurips.cc/virtual/2024/poster/97639
3. "Probabilistic Forecasting for Building Energy Systems: Are Time-Series Foundation Models The Answer?" by Young-Jin Park (Massachusetts Institute of Technology), Jing Liu (Mitsubishi Electric Research Laboratories), François G Germain (Mitsubishi Electric Research Laboratories), Ye Wang (Mitsubishi Electric Research Laboratories), Toshiaki Koike-Akino (Mitsubishi Electric Research Laboratories), Gordon Wichern (Mitsubishi Electric Research Laboratories), Navid Azizan (Massachusetts Institute of Technology), Christopher R. Laughman (Mitsubishi Electric Research Laboratories), Ankush Chakrabarty (Mitsubishi Electric Research Laboratories). Time Series in the Age of Large Models Workshop.
4. "Forget to Flourish: Leveraging Model-Unlearning on Pretrained Language Models for Privacy Leakage" by Md Rafi Ur Rashid (Penn State University), Jing Liu (Mitsubishi Electric Research Laboratories), Toshiaki Koike-Akino (Mitsubishi Electric Research Laboratories), Shagufta Mehnaz (Penn State University), Ye Wang (Mitsubishi Electric Research Laboratories). Workshop on Red Teaming GenAI: What Can We Learn from Adversaries?
5. "Spatially-Aware Losses for Enhanced Neural Acoustic Fields" by Christopher Ick (New York University), Gordon Wichern (Mitsubishi Electric Research Laboratories), Yoshiki Masuyama (Mitsubishi Electric Research Laboratories), François G Germain (Mitsubishi Electric Research Laboratories), Jonathan Le Roux (Mitsubishi Electric Research Laboratories). Audio Imagination Workshop.
6. "FV-NeRV: Neural Compression for Free Viewpoint Videos" by Sorachi Kato (Osaka University), Takuya Fujihashi (Osaka University), Toshiaki Koike-Akino (Mitsubishi Electric Research Laboratories), Takashi Watanabe (Osaka University). Machine Learning and Compression Workshop.
7. "GPT Sonography: Hand Gesture Decoding from Forearm Ultrasound Images via VLM" by Keshav Bimbraw (Worcester Polytechnic Institute), Ye Wang (Mitsubishi Electric Research Laboratories), Jing Liu (Mitsubishi Electric Research Laboratories), Toshiaki Koike-Akino (Mitsubishi Electric Research Laboratories). AIM-FM: Advancements In Medical Foundation Models: Explainability, Robustness, Security, and Beyond Workshop.
8. "Smoothed Embeddings for Robust Language Models" by Hase Ryo (Mitsubishi Electric), Md Rafi Ur Rashid (Penn State University), Ashley Lewis (Ohio State University), Jing Liu (Mitsubishi Electric Research Laboratories), Toshiaki Koike-Akino (Mitsubishi Electric Research Laboratories), Kieran Parsons (Mitsubishi Electric Research Laboratories), Ye Wang (Mitsubishi Electric Research Laboratories). Safe Generative AI Workshop.
9. "Slaying the HyDRA: Parameter-Efficient Hyper Networks with Low-Displacement Rank Adaptation" by Xiangyu Chen (University of Kansas), Ye Wang (Mitsubishi Electric Research Laboratories), Matthew Brand (Mitsubishi Electric Research Laboratories), Pu Wang (Mitsubishi Electric Research Laboratories), Jing Liu (Mitsubishi Electric Research Laboratories), Toshiaki Koike-Akino (Mitsubishi Electric Research Laboratories). Workshop on Adaptive Foundation Models.
10. "Preference-based Multi-Objective Bayesian Optimization with Gradients" by Joshua Hang Sai Ip (University of California Berkeley), Ankush Chakrabarty (Mitsubishi Electric Research Laboratories), Ali Mesbah (University of California Berkeley), Diego Romeres (Mitsubishi Electric Research Laboratories). Workshop on Bayesian Decision-Making and Uncertainty. Lightning talk spotlight.
11. "TR-BEACON: Shedding Light on Efficient Behavior Discovery in High-Dimensions with Trust-Region-based Bayesian Novelty Search" by Wei-Ting Tang (Ohio State University), Ankush Chakrabarty (Mitsubishi Electric Research Laboratories), Joel A. Paulson (Ohio State University). Workshop on Bayesian Decision-Making and Uncertainty.
12. "MEL-PETs Joint-Context Attack for the NeurIPS 2024 LLM Privacy Challenge Red Team Track" by Ye Wang (Mitsubishi Electric Research Laboratories), Tsunato Nakai (Mitsubishi Electric), Jing Liu (Mitsubishi Electric Research Laboratories), Toshiaki Koike-Akino (Mitsubishi Electric Research Laboratories), Kento Oonishi (Mitsubishi Electric), Takuya Higashi (Mitsubishi Electric). LLM Privacy Challenge. Special Award for Practical Attack.
13. "MEL-PETs Defense for the NeurIPS 2024 LLM Privacy Challenge Blue Team Track" by Jing Liu (Mitsubishi Electric Research Laboratories), Ye Wang (Mitsubishi Electric Research Laboratories), Toshiaki Koike-Akino (Mitsubishi Electric Research Laboratories), Tsunato Nakai (Mitsubishi Electric), Kento Oonishi (Mitsubishi Electric), Takuya Higashi (Mitsubishi Electric). LLM Privacy Challenge. Won 3rd Place Award.
MERL members also contributed to the organization of the Multimodal Algorithmic Reasoning (MAR) Workshop (https://marworkshop.github.io/neurips24/). Organizers: Anoop Cherian (Mitsubishi Electric Research Laboratories), Kuan-Chuan Peng (Mitsubishi Electric Research Laboratories), Suhas Lohit (Mitsubishi Electric Research Laboratories), Honglu Zhou (Salesforce Research), Kevin Smith (Massachusetts Institute of Technology), Tim K. Marks (Mitsubishi Electric Research Laboratories), Juan Carlos Niebles (Salesforce AI Research), Petar Veličković (Google DeepMind).
- MERL researchers will attend and present the following papers at the 2024 Advances in Neural Processing Systems (NeurIPS) Conference and Workshops.
See All News & Events for Speech & Audio -
-
Research Highlights
-
Internships
-
CV0075: Internship - Multimodal Embodied AI
MERL is looking for a self-motivated intern to work on problems at the intersection of multimodal large language models and embodied AI in dynamic indoor environments. The ideal candidate would be a PhD student with a strong background in machine learning and computer vision, as demonstrated by top-tier publications. The candidate must have prior experience in designing synthetic scenes (e.g., 3D games) using popular graphics software, embodied AI, large language models, reinforcement learning, and the use of simulators such as Habitat/SoundSpaces. Hands on experience in using animated 3D human shape models (e.g., SMPL and variants) is desired. The intern is expected to collaborate with researchers in computer vision at MERL to develop algorithms and prepare manuscripts for scientific publications.
Required Specific Experience
- Experience in designing 3D interactive scenes
- Experience with vision based embodied AI using simulators (implementation on real robotic hardware would be a plus).
- Experience training large language models on multimodal data
- Experience with training reinforcement learning algorithms
- Strong foundations in machine learning and programming
- Strong track record of publications in top-tier computer vision and machine learning venues (such as CVPR, NeurIPS, etc.).
See All Internships for Speech & Audio -
-
Openings
See All Openings at MERL -
Recent Publications
- , "30+ Years of Source Separation Research: Achievements and Future Challenges", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2025.BibTeX TR2025-036 PDF
- @inproceedings{Araki2025mar,
- author = {Araki, Shoko and Ito, Nobutaka and Haeb-Umbach, Reinhold and Wichern, Gordon and Wang, Zhong-Qiu and Mitsufuji, Yuki},
- title = {{30+ Years of Source Separation Research: Achievements and Future Challenges}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2025,
- month = mar,
- url = {https://www.merl.com/publications/TR2025-036}
- }
- , "No Class Left Behind: A Closer Look at Class Balancing for Audio Tagging", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2025.BibTeX TR2025-037 PDF
- @inproceedings{Ebbers2025mar,
- author = {Ebbers, Janek and Germain, François G and Wilkinghoff, Kevin and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{No Class Left Behind: A Closer Look at Class Balancing for Audio Tagging}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2025,
- month = mar,
- url = {https://www.merl.com/publications/TR2025-037}
- }
- , "O-EENC-SD: Efficient Online End-to-End Neural Clustering for Speaker Diarization", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2025.BibTeX TR2025-031 PDF
- @inproceedings{Gruttadauria2025mar,
- author = {Gruttadauria, Elio and Fontaine, Mathieu and {Le Roux}, Jonathan and Essid, Slim},
- title = {{O-EENC-SD: Efficient Online End-to-End Neural Clustering for Speaker Diarization}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2025,
- month = mar,
- url = {https://www.merl.com/publications/TR2025-031}
- }
- , "Interactive Robot Action Replanning using Multimodal LLM Trained from Human Demonstration Videos", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2025.BibTeX TR2025-034 PDF
- @inproceedings{Hori2025mar,
- author = {Hori, Chiori and Kambara, Motonari and Sugiura, Komei and Ota, Kei and Khurana, Sameer and Jain, Siddarth and Corcodel, Radu and Jha, Devesh K. and Romeres, Diego and {Le Roux}, Jonathan},
- title = {{Interactive Robot Action Replanning using Multimodal LLM Trained from Human Demonstration Videos}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2025,
- month = mar,
- url = {https://www.merl.com/publications/TR2025-034}
- }
- , "Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2025.BibTeX TR2025-029 PDF Software
- @inproceedings{Masuyama2025mar,
- author = {Masuyama, Yoshiki and Wichern, Gordon and Germain, François G and Ick, Christopher and {Le Roux}, Jonathan},
- title = {{Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2025,
- month = mar,
- url = {https://www.merl.com/publications/TR2025-029}
- }
- , "Leveraging Audio-Only Data for Text-Queried Target Sound Extraction", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2025.BibTeX TR2025-033 PDF
- @inproceedings{Saijo2025mar2,
- author = {Saijo, Kohei and Ebbers, Janek and Germain, François G and Khurana, Sameer and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{Leveraging Audio-Only Data for Text-Queried Target Sound Extraction}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2025,
- month = mar,
- url = {https://www.merl.com/publications/TR2025-033}
- }
- , "Task-Aware Unified Source Separation", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2025.BibTeX TR2025-032 PDF
- @inproceedings{Saijo2025mar,
- author = {Saijo, Kohei and Ebbers, Janek and Germain, François G and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{Task-Aware Unified Source Separation}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2025,
- month = mar,
- url = {https://www.merl.com/publications/TR2025-032}
- }
- , "Keeping the Balance: Anomaly Score Calculation for Domain Generalization", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2025.BibTeX TR2025-030 PDF
- @inproceedings{Wilkinghoff2025mar,
- author = {Wilkinghoff, Kevin and Yang, Haici and Ebbers, Janek and Germain, François G and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{Keeping the Balance: Anomaly Score Calculation for Domain Generalization}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2025,
- month = mar,
- url = {https://www.merl.com/publications/TR2025-030}
- }
- , "30+ Years of Source Separation Research: Achievements and Future Challenges", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2025.
-
Videos
-
Software & Data Downloads
-
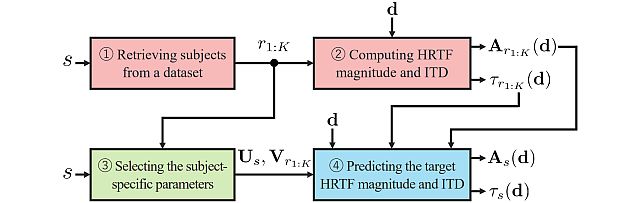
Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization -
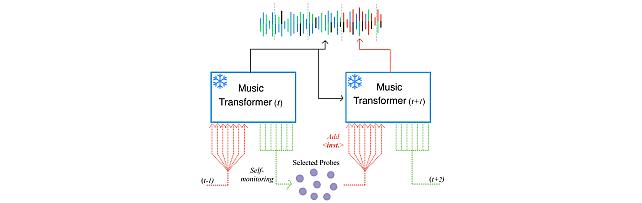
Self-Monitored Inference-Time INtervention for Generative Music Transformers -
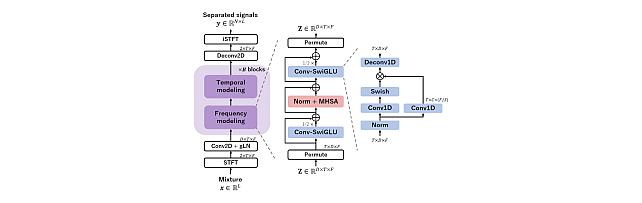
Transformer-based model with LOcal-modeling by COnvolution -
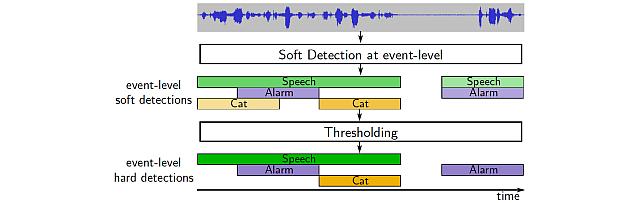
Sound Event Bounding Boxes -
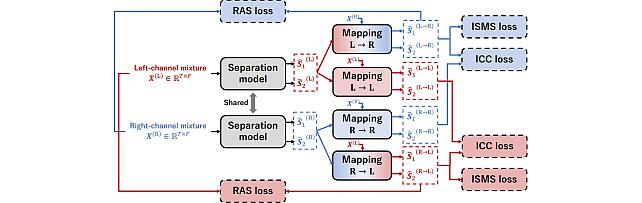
Enhanced Reverberation as Supervision -

Neural IIR Filter Field for HRTF Upsampling and Personalization -
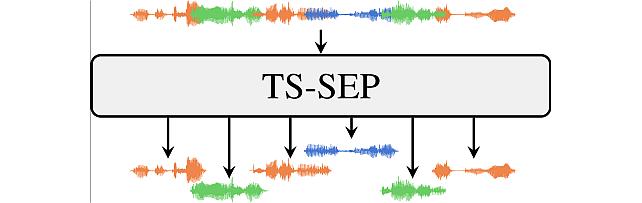
Target-Speaker SEParation -

Hyperbolic Audio Source Separation -

Audio-Visual-Language Embodied Navigation in 3D Environments -

Audio Visual Scene-Graph Segmentor -

Hierarchical Musical Instrument Separation -

Non-negative Dynamical System model
-


















